While I was at the PASS Summit this year, I was sitting in Paul Turleys’s (b|t) session on creating integrated BI solutions. Paul was talking about how ETL takes up most of a BI solution’s development lifetime, regardless of how you planned for it. That’s when someone from the audience asked the question: “…methodology or tool in the MS stack to shorten the time taken for ETL?”. Paul’s answer was: “There’s no silver bullet, But I’m going to say it’s Power Query”. This got me thinking, since for a few weeks, my team had been struggling to get data cleansed on the project that they were working on.
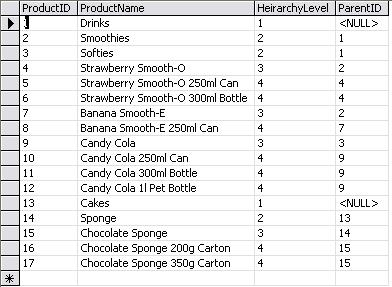
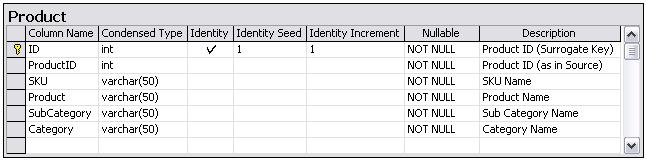
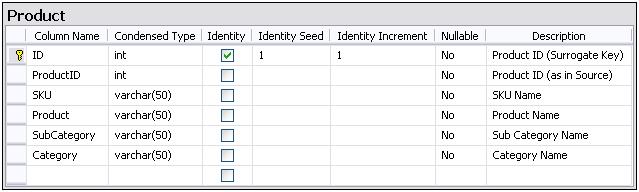
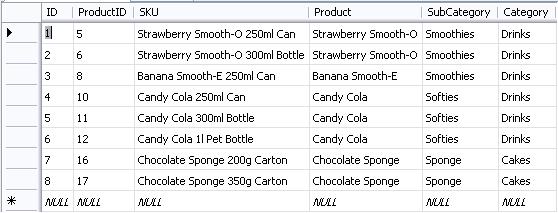
Despite having a data profiling document, which documented how source data mapped to the data model, along with the rules that needed to be applied to these data, such as nullability, constraints, valid domain values and so forth, bad data continued to come in. Apart from bad data, there were scenarios that were not identified nor thought of before that were coming in with the data. Though we do usually expect some amount of bad data or anomalies, which can be reported on, this was pretty bad. We needed to have a data set that would not fail the ETL so that it can be at least tested for all business logic that we had identified as requirements.
The issue was that the team had to build the Integration Services packages first, before running it to finally find out the various data problems that kept spitting out. So, it took a while for the developer to identify the problem, realize the data issue, report it to the client, have it fixed by the client, (sometimes do a fix on the package) and repeat. There were times when I had to jump in to help figure out what the data problems were. But because getting onto a tool (specially non-Microsoft), connecting to the source, and then writing SQL queries to retrieve and check the data was quite a slow process, I preferred using Power Query.
Power BI is a self-service tool; it can connect to many different types of data source, the best thing about it is the ease of pulling in data, building joins, filtering, sorting and perform all the data manipulations that you want do is made super easy. And you could just save it all in one just file, and use it the next time you want it. So I get it (or at least formed an impression in my head), and related to it when Paul said “Power Query” as the tool to speed up the life time of ETL development.
Explaining how you could go about it is another post for the future, but I am presenting it at the Sri Lankan Data Community Meetup on Nov 29th in Colombo,if you are interested 😉