Forgive the cliché up there, but I could not resist it!
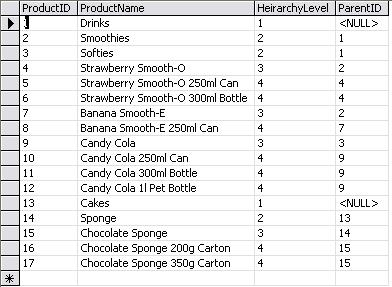
In data warehousing (and data marting), we usually use the popular dimensional model (or the star schema) to design the data warehouse (or data mart). And it is a common conclusion that your fact tables are going to be huge. And would be updated on a scheduled basis. Could be monthly, could be daily and from recent times, even hourly or sometimes (God forbid) on the minute!
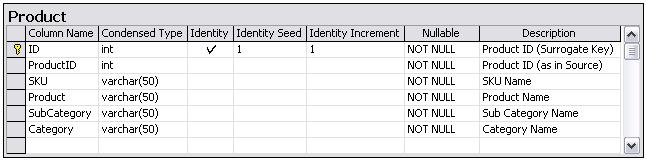
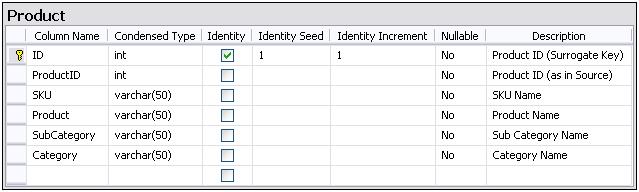
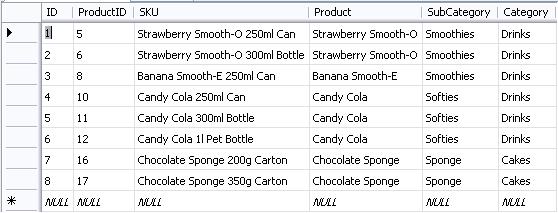
Now, there have been arguments in the past as to whether we actually need to create primary key constraints, and especially if foreign key constraints need to be created between the fact table and the related dimension tables. Do we need to create indexes on the different columns.
Some may be shocked by such a question. I mean is this something that need to be doubted? Of course you need keys. Where else some others may be quite liberal and say, No! Of course you don’t need these keys and indexes. There are valid points to counter-argue each approach. There can also be a middle path.
In order to fuel this fire I have a question going on in the Beyond Relational BI Quiz 2011. This is a great place where you can prove your point of what you think. Points will be rewarded based on how well your arguments are presented. And then you get a chance to win an Apple iPad if your aggregate of the whole quiz is at the top.
The question goes as follows:
You are designing a data mart that results in a star schema on an SQL Server 2008 R2 server. A fact table with 7 dimensions, initially containing records in the region of 2,000,000. You expect the fact table to grow increasing by around 50,000 each month. Data loads happen on a weekly basis, and sometimes on an ad-hoc basis twice or thrice a month. Would you or would you not design primary key constraints, foreign key constrains and indexes for the data mart? If so how and why would you proceed, or why would you not? Discuss.
Like I said, points would be awarded based on how well you present your arguments. Click Here to Submit an Answer. Good luck!